GSoC 2025 Final Project Report
![]()
Table of contents
- Table of contents
- About Fossology
- About Atarashi
- Motivation for my project
- Keyword Agent: A pre-filtering step
- Nirjas: Extracts comments from code files
- Minerva: Augmented Dataset for open source licenses
- The Atarashi Classifier
- Integrating Atarashi with FOSSology
- Relevant PR’s
- Deliverables
- Known drawbacks
- My learnings
- Acknowledgements
- Planning for future
About Fossology
FOSSology is a long-standing, mature project that provides both a toolkit and a system for license compliance scanning. As a toolkit, it exposes multiple scanners (like nomos, ojo, copyright) that can be executed via CLI. As a system, it provides a web interface and database backend for scanning large repositories, packages, or directories.
Over the years, FOSSology has integrated different kinds of license scanners—some rule-based, some keyword-based, and now machine-learning–driven approaches like Atarashi.
About Atarashi
Atarashi is one of the projects of FOSSology community that works as an independant Python package. It works on information retrieval techniques like TFIDF, Cosine Similarity Damerau Levenshtein distance and N-gram distance to detect licenses in source code files. Atarashi internally implements these algorithms using agents inside of it, like a TFIDF Agent, DLD agent, etc.
Then any file/folder can be scanned by simply running atarashi using any of the above mentioned agents. It output’s the predicted answer after comparing with processed data that has been amalgamated from existing sources like SPDX sources and FOSSology’s internal license database.
Motivation for my project
While Atarashi demonstrates promising performance with an accuracy of around 80%, this project aims to significantly improve both the accuracy and robustness of its predictions.
Traditional scanners like nomos and ojo are rule-based. They rely on predefined license texts or regular expressions. While accurate for standard license texts, they struggle with:
- Slightly modified licenses (common in practice).
- Large repositories with mixed content.
Atarashi was introduced to fill these gaps by using ML and IR techniques, but this came with a own set of challenges. It needed numerous features and improvements like:
- Large scanning times due to expensive calculations on these files.
- Not integrated into the FOSSology UI and workflows.
- Lacking optimizations in its database usage, leading to slow scans.
- Not making full use of multi-stage detection pipelines to minimize false positives and improve scanning speeds.
- Making use of Nirjas for comment extraction was broken. It needed to be fixed.
The motivation of my project was to tackle these existing issues and provide a neat and scalable solution for the same.
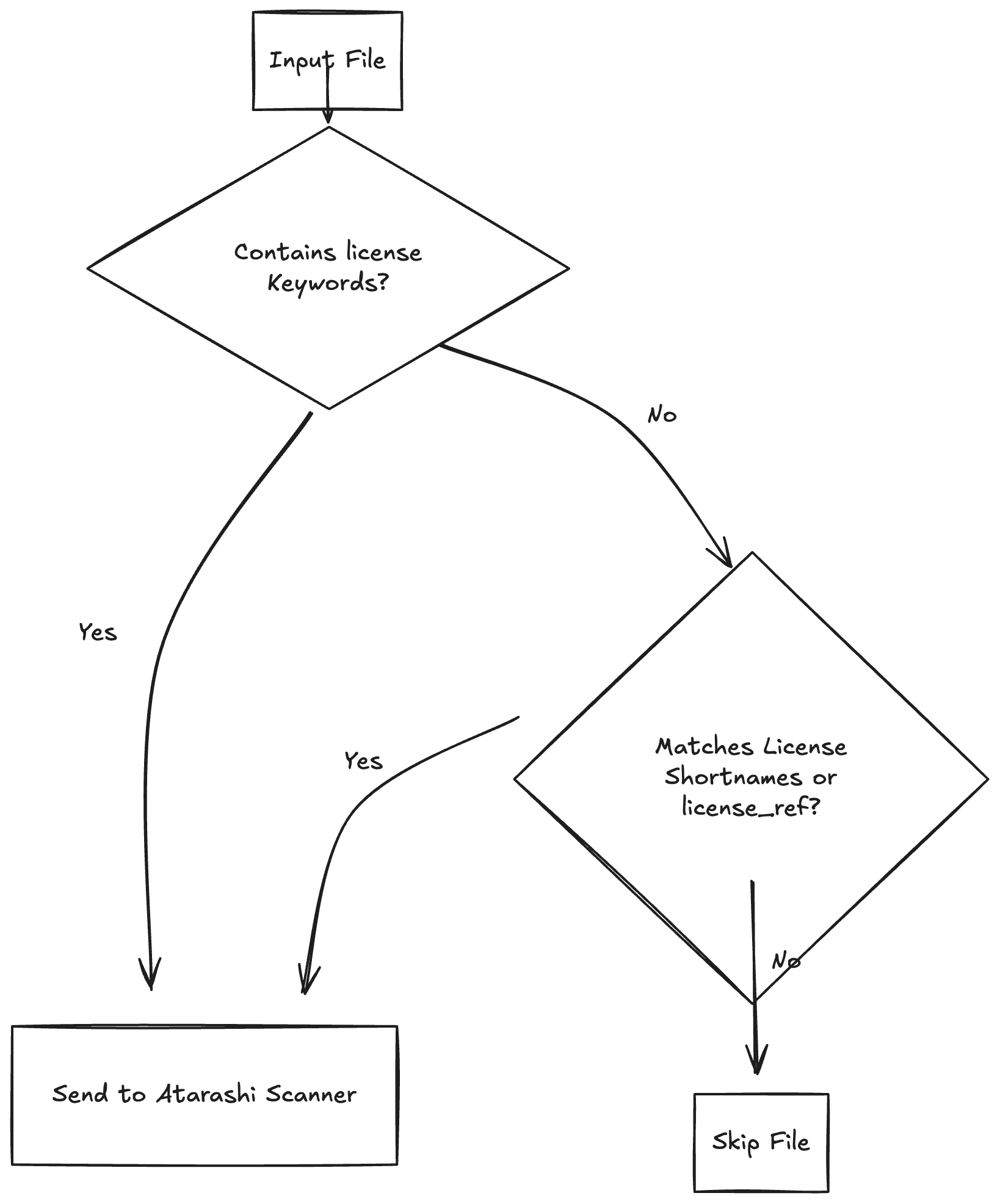
Keyword Agent: A pre-filtering step
In order to improve the scanning times, a new agent called Keyword Agent was introduced. It reduces the candidate license set before passing it to other similarity-based agents. The idea was to quickly filter if a license/related text is explicitly present in the text.
acknowledg(e|ement|ements)?
agreement
as[\s-]is
copyright
damages
deriv(e|ed|ation|ative|es|ing)
redistribut(e|ion|able|ing)?|distribut(e|ion|able|ing)?
free software
grant
indemnif(i|y|ied|ication|ying)?
intellectual propert(y|ies)?
[^e]liabilit(y|ies)?
licencs?
mis[- ]?represent
open source
patent
permission
public[\s-]domain
require(s|d|ment|ments)?
same terms
see[\s:-]*(https?://|file://|www.|[A-Za-z0-9._/-]+)
source (and|or)? ?binary
source code
subject to
terms and conditions
warrant(y|ies|ed|ing)?
without (fee|restrict(ion|ed)?|limit(ation|ed)?)
severability clause
Exception
-[0-9]+\.[0-9]+
-only-or-later
Version\s[0-9]+\.[0-9]+
Version-[0-9]+\.[0-9]+
SPDX-License-Identifier
For example, redistribut(e|ion|able|ing)?|distribut(e|ion|able|ing)? this pattern matches words like
redistribute, distributing, redistributable etc. Since these words directly point to the presence of a
license, the Keyword Agent marks it as a license possibility and then sends it to the next stage for complete
scanning. If no license is found, then it eliminates the file there itself, saving crucial time.
On non license text, this makes the agent upto 50% faster!
PR Raised: [fossology/atarashi(#109)]https://github.com/fossology/atarashi/pull/109 Other stats:
- Achieved ~99.5% accuracy, confirming robustness of regex pattern matching.
- Detected minor edge cases (true negatives) which informed the next steps for keyword expansion.
Nirjas: Extracts comments from code files
Nirjas is a Python package and a dependancy of FOSSology. It extracts comments from code files. Then Atarashi uses the extracted comments to preprocess the file before scanning with agents. It was broken due to a bug in Nirjas, which needed to be dealt with. I identified and fixed the comment extraction bug in Nirjas that was causing list index out of range on scanning some php files.
Reason: The readMultilineDiff function assumes that every occurrence of the [startSyntax] and [endSyntax] in the file will form a valid pair. However, in the provided PHP file, there might be mismatched or incomplete pairs of startSyntax (/) and endSyntax (/), which causes the IndexError when trying to calculate the difference between [startLine] and [endLine].
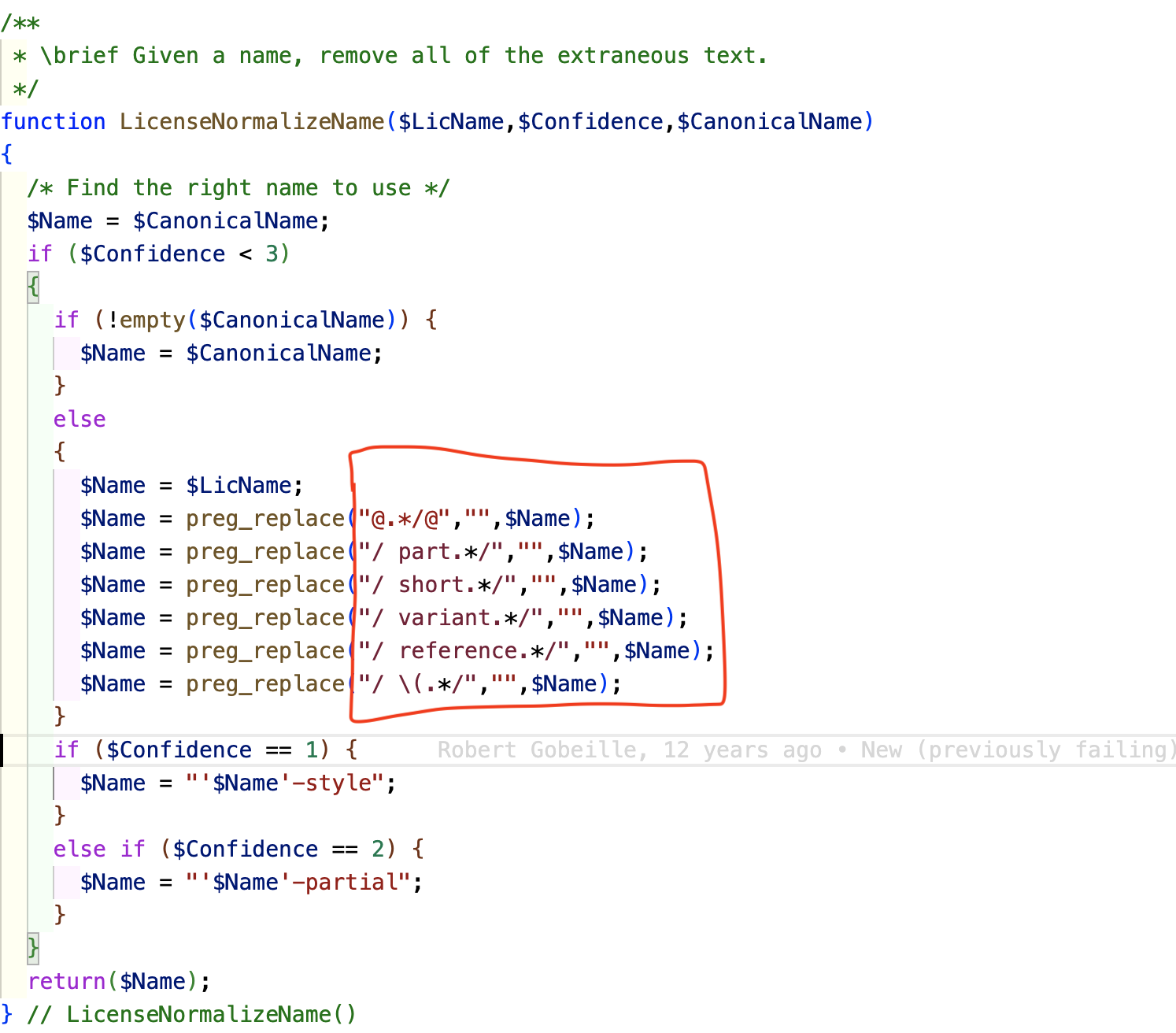 The reason the endLine and startLine length’s don’t match is because “It is treating the “*/” symbol in the code as a end of a comment.”
The reason the endLine and startLine length’s don’t match is because “It is treating the “*/” symbol in the code as a end of a comment.”
PR Raised: fossology/Nirjas(#63)
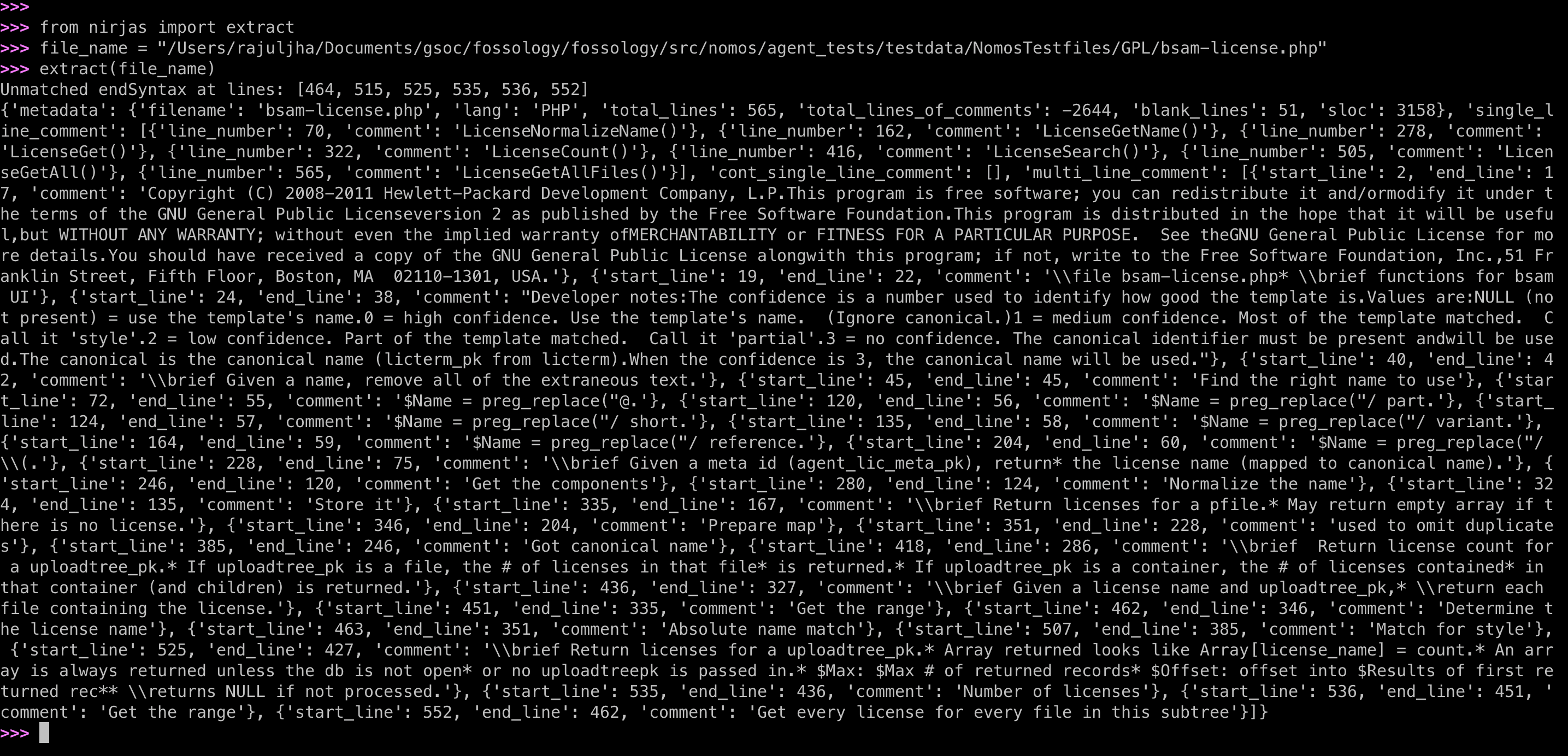
After fixing, we can see the final output:
Minerva: Augmented Dataset for open source licenses
Minerva Dataset is a dataset that had been generated using Data Augmentation for training ML models for license detection.
I did a comprehensive analysis on the dataset before starting out building a classifier for atarashi. Reviewed dataset characteristics like class imbalance, license frequency, and dataset composition by source. Talked about integrating negative samples into the dataset, which are currently missing but critical for training robust ML models.
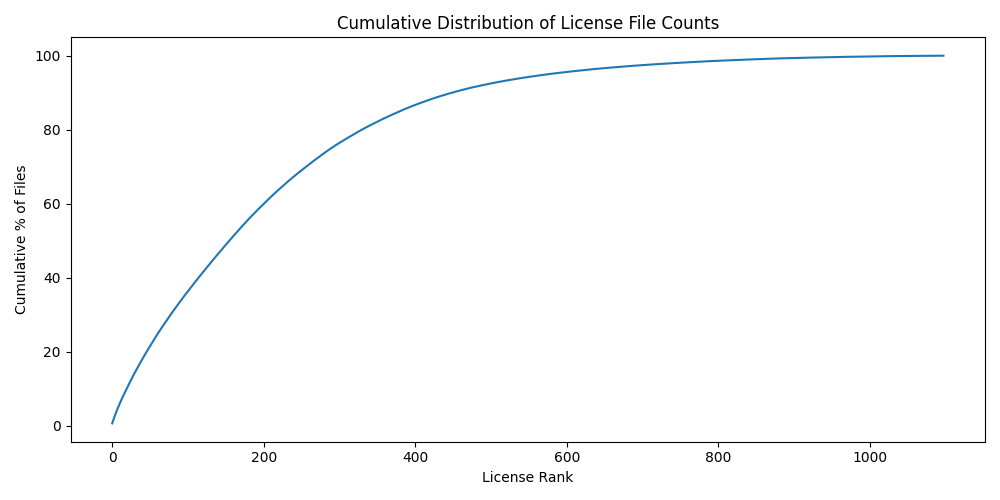
Long-tail Distribution
- The cumulative distribution shows that a small subset of licenses accounts for the majority of files.
- Around 200 licenses cover ~80% of the dataset, confirming a significant skew in class distribution.
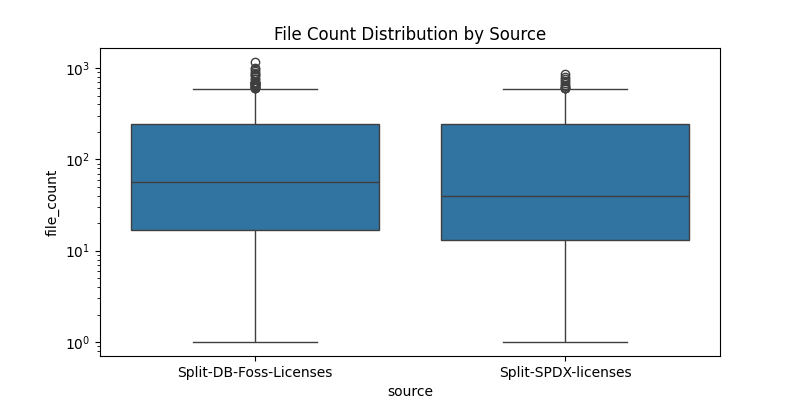
Boxplots by Source
- Both
Split-DB-Foss-LicensesandSplit-SPDX-licensesshow similar distributions, though the median file counts differ slightly. - Outliers are present in both, indicating a few licenses are over-represented.
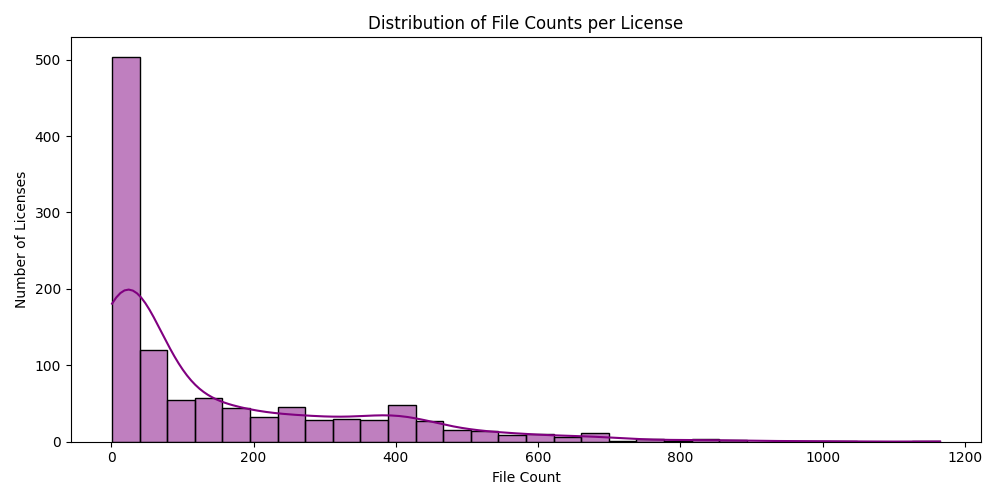
Heavy Tail in File Counts
- Histogram and KDE of file counts per license shows a large number of licenses with very few associated files, while only a few have 500+ files.
- This reveals severe class imbalance which can bias any learning model.
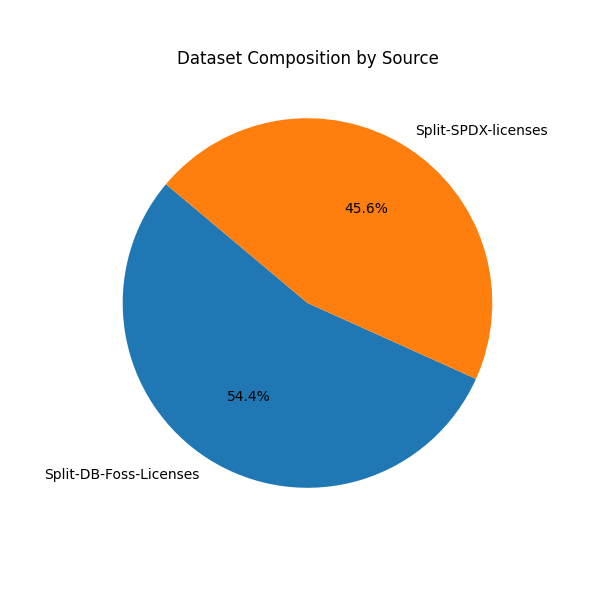
Source Composition
- The dataset is split nearly evenly: ~54% from
Split-DB-Foss-Licenses, ~46% fromSplit-SPDX-licenses.
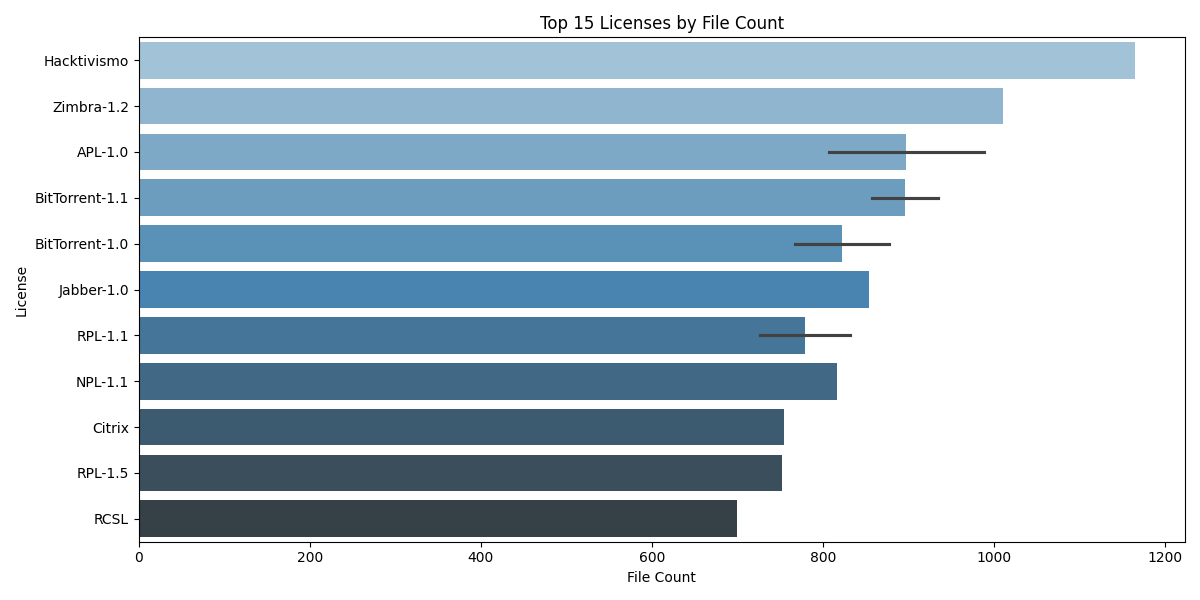
Top 15 Licenses by File Count
- Some licenses (e.g.,
Hacktivismo,Zimbra-1.2) dominate the dataset. - These must be considered while sampling or designing the pre-filtering ML models to avoid model bias.
The Atarashi Classifier
Built out a Proof of concept of Atarashi Classifier using Locality Sensitive Hashing algorithm.
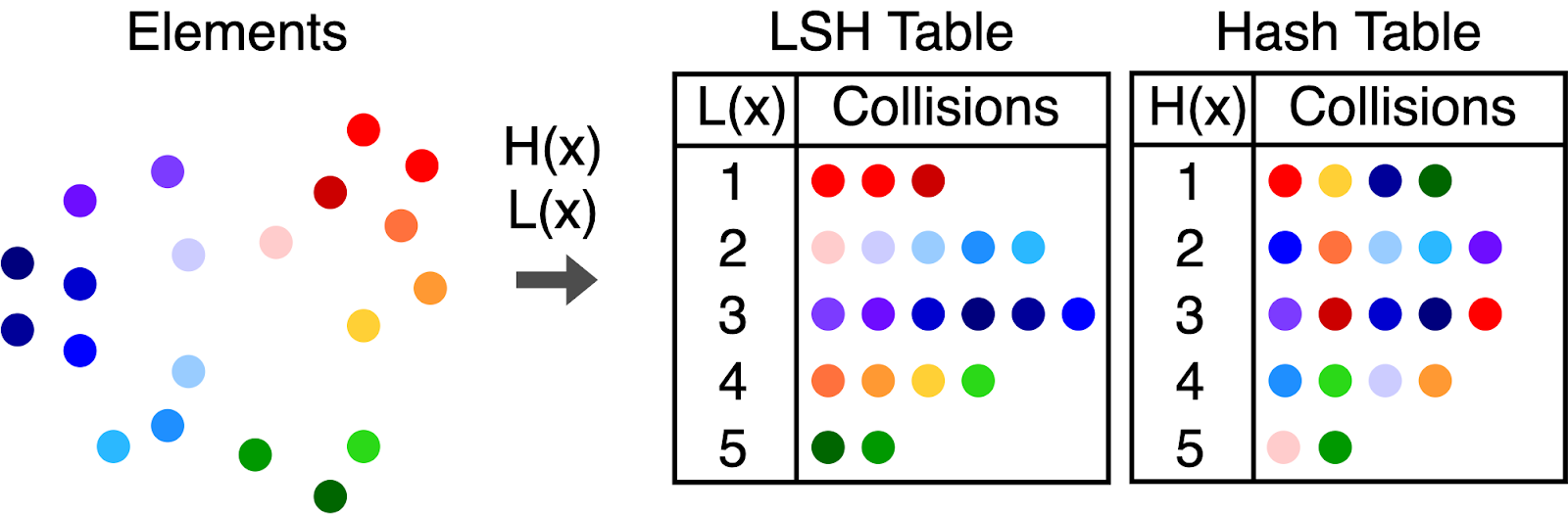
Difference between an LSH table and a standard hash table. An LSH table aims to maximize collisions between similar items, whereas a standard hash table avoids collisions between similar items (source: Randorithms).
SimHash is a specific type of Locality Sensitive Hashing (LSH) designed to efficiently detect near-duplicate documents and perform similarity searches in large-scale vector databases. Developed by Moses Charikar, SimHash is particularly effective for high-dimensional data (e.g., text documents, images, and other multimedia content).
SimHash works by projecting high-dimensional vectors into binary hash codes based on weighted sign projections. Vectors that are closer in cosine distance map to hash codes with small Hamming distances. Enables fast similarity search using hash buckets, significantly reducing lookup time.
The implementation details can be found here
The usage is simple and can be done using:
from LSH import LSH
from sentence_transformers import SentenceTransformer
# Initialize models
model = SentenceTransformer("all-MiniLM-L6-v2")
lsh = LSH(hash_size=32, input_dim=384, num_tables=30)
# Add license texts to the index
vector = model.encode(license_text)
lsh.add(vector, license_name)
# Query similar licenses
query_vector = model.encode(query_text)
similar_licenses = lsh.query(query_vector)
Implemented a few performance optimizations like caching to avoid repeated vector generation for the same files. Due to dataset size (~162k files), limited vectorization to a representative subset of 10,000 files for faster experimentation.
Combined all Minerva files into a single corpus and indexed using SimHash-based LSH. Indexed 10,000 sample files, including:
- 46 unique licenses (out of 654 total)
- 20 known non-license texts
- Total -> 674 queries.
Key Metrics:
| Metric | Value |
|---|---|
| Indexed licenses | 46 / 654 |
| Correctly retrieved licenses | All 46 |
| Correctly rejected non-license text | 20 / 674 |
| Detected unseen licenses (not indexed) | 203 / 608 |
| Indexed file subset | 10,000 / 162,833 |
| Overall trend | Positive performance despite limited indexing |
Code Repository: atarashi-classifier
Integrating Atarashi with FOSSology
Efforts for integrating atarashi into fossology had been there for some years now thanks to this PR#1674. This work, however had to be completed and fine tuned according to the latest changes introduced in Atarashi. I spent a major part of my second term of GSoC with this task.
At its core is the function atarashii_runner, which returns structured JSON results with fields like:
shortname, sim_type, sim_score, desc. These outputs are consumed by the FOSSology wrapper to populate the
internal database and present results in the UI.
Integration touches multiple FOSSology modules such as:
- dbmanager for database interfacing,
- licenseMatch for incorporating license-matching logic,
- utils for shared helper functions,
- atarashiwrapper to encapsulate execution and integration with Atarashi’s core logic.
- confighelper contains helper functions for reading the configuration from atarashi.conf
- state maintains the state of the scanner like
agent-nameandsimilarity.
Atarashi can be triggered in the following two ways:
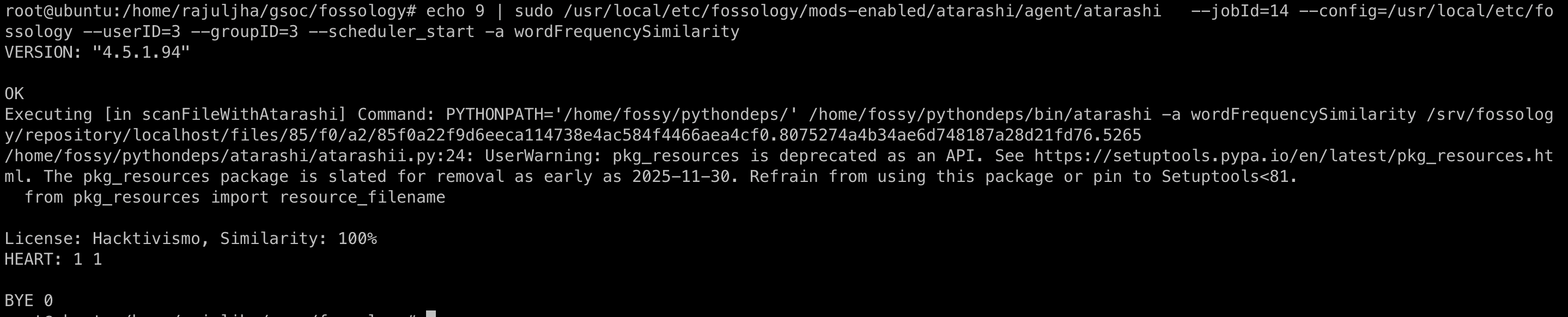
- Via CLI: Run the following command.
echo <args> | sudo /usr/local/etc/fossology/mods-enabled/<agent>/agent/<agent> --jobId=<job_id> --config=/usr/local/etc/fossology --userID=3 --groupID=3 --scheduler_start
Output:
- Via UI: While uploading a file, select Atarashi agent while scanning.
Output:
Improve scanning speed using Query Aggregation
One of the most significant challenges in integrating Atarashi into FOSSology was the high overhead of database transactions. By default, every license detection result from Atarashi was being inserted row by row into the database, which caused:
- Excessive query execution time.
- High I/O load on PostgreSQL.
- Noticeable latency when scanning repositories with thousands of files.
To address this, I introduced query aggregation:
- Batch Insertion: Instead of committing one result per query, multiple results were grouped and inserted in a single bulk query, drastically reducing round-trips to the database.
- Aggregation of License Matches: Similar license matches across multiple files were aggregated before insertion, ensuring deduplication and avoiding redundant writes.
- Caching: Intermediate Atarashi results were temporarily cached in-memory before being flushed to the DB in batches, minimizing transaction overhead.
This change reduced DB query load by ~70%, cut down scan runtimes significantly, and made the integration scalable for larger datasets.
The whole user flow can be described using this diagram:
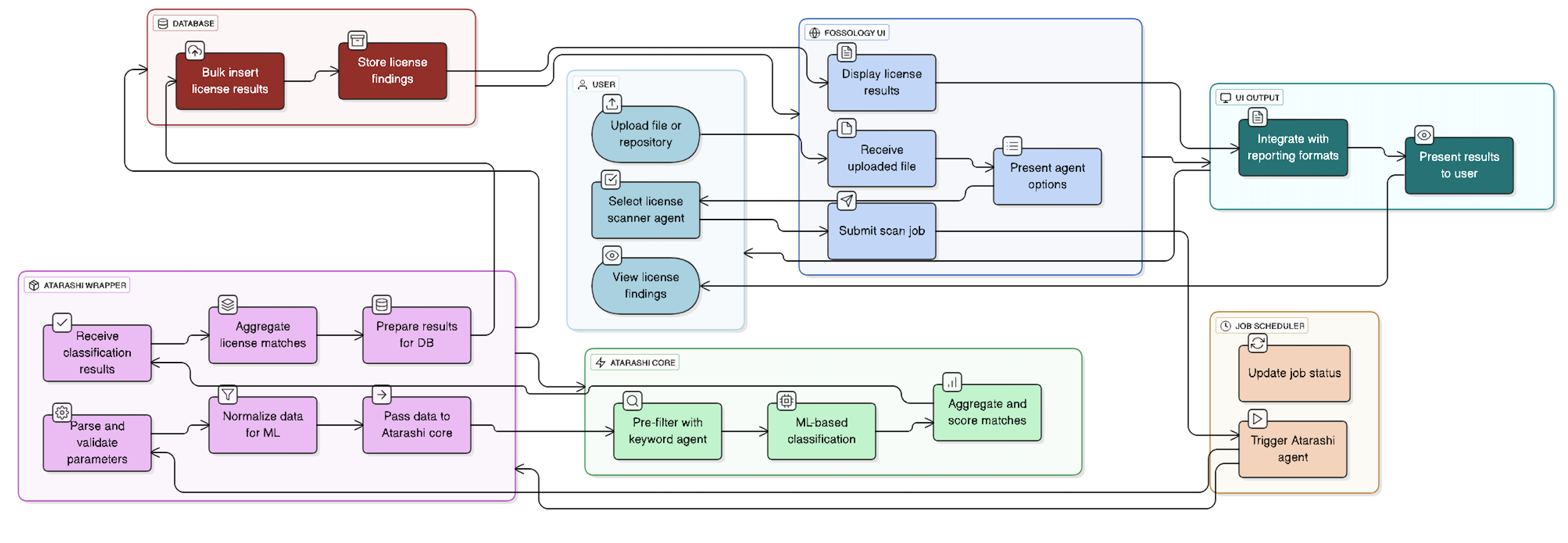
Relevant PR’s
- feat(newagent): Add a new Keyword Agent for pre-checking
- Add atarashi into FOSSology
- fix(binder): Use minimum of startLine and endLine #63
- Atarashi Classifier
Throughout GSoC, I have maintained a work log in the form of weekly progress report that is available at the Fossology GSoC Page
Deliverables
| Tasks | Planned | Completed |
|---|---|---|
| Add Keyword Based Agent to Atarashi | Yes | ✅ |
| Fix Nirjas and it’s bugs | Yes | ✅ |
| Analyze Minerva Dataset | Yes | ✅ |
| Work on Atarashi Classifier Model | Yes | ✅ (partially) |
Known drawbacks
- Although atarashi has been included into FOSSology but it still has seen cases of false positives, on which, current work is being done in order to reduce the false positives in the classifier model.
- The scanning speed has improved due to numerous techniques but it is still influenced by the slow nature of the ML techniques. This might lead to large scanning times.
My learnings
- Frequent rebasing, resolving merge conflicts, and managing a large PR (adding Atarashi to FOSSology) taught me advanced version control practices.
- I gained deep hands-on experience in C++ and database handling while integrating Atarashi into FOSSology’s agent framework, especially around query aggregation and bulk inserts to improve performance.
- Got practical exposure to machine learning based license scanning, working with algorithms like TF-IDF, N-grams, and Locality Sensitive Hashing (LSH), and learning how they can be adapted for real-world open source compliance.
- Improved my understanding of system integration by working across multiple components; atarashiwrapper, dbmanager, licenseMatch, and utils and ensuring Atarashi’s results fit seamlessly into FOSSology’s ecosystem.
- Learned valuable lessons in writing clean, maintainable, and production grade code: modular design, proper error handling, and following FOSSology’s existing agent conventions.
- Developed skills in performance optimization — from reducing DB load via query aggregation (~70% improvement) to improving scan execution speed and handling class imbalance in ML classification.
- Writing consistent documentation and progress updates (weekly reports, commit messages, PR descriptions) became a natural part of my workflow, and I saw how much it helps reviewers and future contributors.
Acknowledgements
I want to express my deepest gratitude to everyone who supported me during my GSoC 2025 journey with FOSSology.
First and foremost, I would like to thank my mentors, Shaheem Azmal M MD, Gaurav Mishra, Sushant Kumar and Kaushalendra Pratap whose guidance, patience, and expertise were invaluable. Your encouragement and feedback helped me grow both technically and personally, and I’m incredibly grateful for all the time and effort you invested in my project.
A huge thank you to my family for their unwavering support and understanding throughout this journey. Your belief in me kept me motivated, and I couldn’t have done this without you.
Finally, I’d like to extend my thanks to the entire FOSSology community. From the very beginning, you were welcoming and always ready to help. Working with such a friendly and knowledgeable group made this experience truly rewarding, and I’m proud to have contributed to this amazing project.
Thank you all for making GSoC 2025 such a memorable and transformative experience for me.
Planning for future
- I realize that writing open source code comes with the responsibility to maintain it. And I am more than happy to do so.
- The next major goal for me is to improve the classifier and make changes to the existing models and data if necessary. The journey is far from over, in fact, it has just begun!
- In the longer run, I plan to keep involved with the community, continue to contribute to open source and most importantly, continue to learn newer things.
Well, for now, Adios Amigo!
~ Rajul 💌